|
Module
One Notes |
|
1.1:
Introduction to Quantitative Analysis
This is a course about the use of
quantitative methods to assist in decision making. The subject matter makes up
the discipline known as decision sciences, or you might hear it
called management science or operations research.
We will be covering a number of descriptive and prescriptive mathematical
models that have proven useful to managers, generally since World War II,
although some of the models date back to the early 1900's. Mathematical models
are simply representations of reality that provide a framework for a scientific
approach to the study of managerial problems.
Models also help us gain insight into relationships such as the relationship
that exists between an objective and a constraint. For example, we will be
using linear programming prescriptive models to represent the relationship
between a profit maximization objective and one or more limited resource
constraints. Suppose a company
manufactures two products, X and Y. Product X has a
profit contribution of $100 and Y $300. The mathematical expression for
maximizing profit is simply:
Maximize Profit = 100 X + 300 Y
What should this company do to maximize profit? That's right, make an infinite number of Y's! But the real world presents constraints to every operation. Suppose that it takes 4 hours of labor to assemble an X, and 20 hours of labor to assemble each Y. If there are 140 hours of labor available in the next production period, we can expand the problem as follows:
Maximize Profit = 100 X + 300 Y
Subject to Labor Constraint: 4 X + 20 Y < 140
The labor constraint equation uses numbers to represent the technological rate of resource consumption of the two products (the coefficients of 4 and 20), as well as a less than or equal sign to put an upper limit on the 140 hour labor constraint. If we wanted to continue our strategy of making all Y's and no X's, we see that we could make 7 Y's by using all of the 140 hours of labor.
Let X = 0, then
4 (0) + 20 Y = 140 gives
20 Y = 140 or
Y = 140/20 = 7
Solving for Profit, we get:
Profit = 100 (0) + 300 (7) = $2,100
But there is another
alternative worth examining. We could make all X's and no Y's. Since X's
require much less labor, we can make 35 of them, at a profit of $3,500 - the
better alternative. To be sure we have the best or optimal solution
that maximizes our profit criteria, we would need the
mathematical model to check the profit contribution of all other product mix
combinations.
Obviously, this is a small problem that can be solved by observation. Imagine
what the linear program problem formulation looks like for an auto manufacturer
which much select between perhaps 10 models of one make of car subject to a
multitude of labor, equipment, and market constraints. For these large problems
we need a more formal problem solving process.
The scientific approach to the study of managerial problems incorporates a
problem solving process. The text presents a seven-step process:
1. Identify and define the problem
2. Determine the set of alternative solutions
3. Determine the criterion or criteria that will be used to evaluate the alternatives.
4. Evaluate the alternatives (using an appropriate quantitative method or model).
5. Choose an alternative
6. Implement the selected alternative (the decision)
7. Evaluate the results and determine if a satisfactory solution has been obtained.
Decision-making is concerned with the first five steps and will
be our focus through this course. The first three steps are concerned with
structuring the problem, and the next two with analysis. When the manager adds
qualitative considerations to the selection process, and follows through with
implementation and evaluation, the problem solving process is complete.
We will start off the course with descriptive models that
describe outcomes for selected alternatives, and in that manner assist the
decision-maker in selecting between alternatives. These models include decision
analysis, forecasting, project management, and queuing or waiting line models.
For example, I hope you will
enjoy the module on queuing or waiting lines simply
because most of us probably have "war stories" about waiting in lines
somewhere at some time. Did you know that there are descriptive models that
predict how many customers will be standing in a given line,
and for how long, given that we know the customer arrival rate and system
service rate inputs? In this module, we will introduce models that will prove
to you why banks and Disney utilize a single line/multiple server configuration
to minimize waiting time in line for their customers.
I hope you will also enjoy the forecasting module where simple
mathematical techniques are used to discover patterns such as trend and
seasonality in our data. In the forecasting module, we drive home how important
it is to measure and report the reliability of a forecast - almost as important
as the forecast itself.
Simulation
studies enable an objective estimate of the probability of a loss (or gain)
which is an important aspect of risk analysis.
One of the main advantages of simulation over analytical models is the
ability to use probability distributions that are unique to the system being
studied.
The project management
material helps us learn about the importance of focusing on critical
activities, and on the concept of slack resources. The decision analysis
material we start with helps us appreciate the value that can be placed on
information as we study a model designed to help manager select between
decisions when faced with several state of nature scenarios.
We wrap up the course with linear and integer programming
optimization models that select alternatives which
provide the best value for the problem criteria subject to structural and
environmental constraints. An example of an optimization problem was presented
at the beginning of this section. Optimization models are very powerful and are
used to assist decision-makers in capital budgeting, project selection,
resource allocation, and scheduling and transportation problems.
Let's now get started with our first subject, Decision Analysis.
1.2:
Structuring the Decision Analysis Problem
Decision analysis,
our first quantitative method in this course, is concerned with selecting an
option or alternative course of action (the decision) given prior
knowledge of its outcome (called a payoff) for various future
scenarios (called states of nature or events). The decision-maker
has control over the process of selecting an alternative course of action, but not
over the states of nature, at least not in the short run. Let's illustrate
these terms with an example.
Suppose a manufacturer has three alternative courses of action for the next production period. They can make their product (we will use the symbol d1 to represent the first decision alternative), buy their product from another manufacturer and sell it to their customers (d2), or they can do nothing in the next production period (d3). Suppose further that the manufacture has a simple forecast for the next productions period: demand will be low (state of nature symbol s1) or high (s2). The final input for the structure of the decision analysis problem is the outcome or payoff resulting from each state of nature/decision combination.
A convenient structure for
displaying the decision alternatives, states of nature and payoffs is a payoff
table.
Table 1.2.1
|
Decision Alternatives |
States
of Nature |
|
|
Low Demand, s1 |
High Demand, s2 |
|
|
Make Product, d1 |
($ 20,000) |
$ 90,000 |
|
Buy Product, d2 |
$ 10, 000 |
$ 70,000 |
|
Do Nothing, d3 |
$ 5,000 |
$ 5,000 |
The payoff table shows, for example, that making the product leads to a profit of $90,000 should the demand turn out to be high, or a loss of $ 20,000 if demand is low. I will follow the convention in the text by giving the symbol Vij to represent the payoff associated with decision alternative i and state of nature j.
To continue with the table, buying the product shows that the manufacturer can avoid a loss, compared to making the product, if the demand turns out to be low since the manufacturer avoids paying fixed production costs. If the demand is high, the manufacturer makes a profit, but not as much as if they made the product since they miss the production economies of scale. If the manufacturer does nothing, a small profit is earned from selling existing inventory that just meets a low level of demand (both V31 and V32 equal $5,000).
Another way to display the
structure of the decision problem is with a decision tree.
Figure 1.2.1
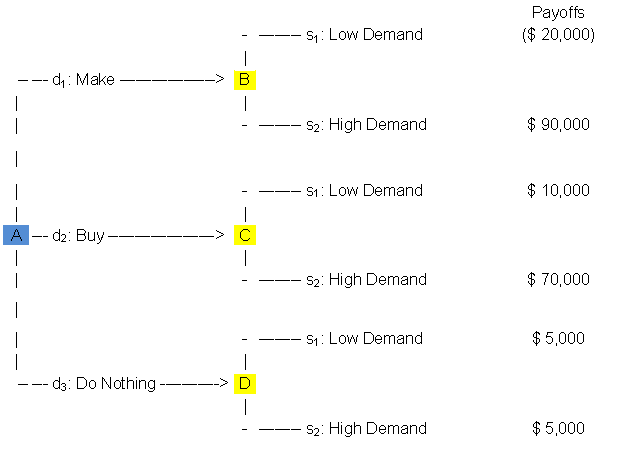
In this decision tree, the
cell labeled A denotes a decision node, followed by its three decision
branches. The cells labeled B, C and D denote state of nature nodes which are
each followed by the two state of nature branches. Payoffs are shown at the
terminal end of each state of nature branch.
Structuring the decision problem, as in formulation of all quantitative models,
establishes the first major benefit of these formal methods of decision making.
That is, the decision-maker is required to formally consider many of the
important aspects of a decision problem during the problem-structuring phase.
These aspects may be overlooked when the decision-maker uses "gut
feel" or some other purely qualitative technique to make decisions.
After the problem is structured, we can now turn to its analysis: selecting one
of the possible decision alternatives according to predetermine selection
criteria. There are two major approaches in decision analysis that depend on
the availability of information on the states of nature. One approach is called
decision making without probabilities, and the other, decision making with
probabilities.
1.3:
Decision Making without Probabilities
In this approach, the
decision-maker has no information concerning the relative likelihood of each of
the states of nature. It is sometimes called "decision making under
risk." There are three classic criteria used in decision-making strategies
without probabilities, as described in the next three subsections.
Optimistic Criterion
In this strategy, the decision-maker evaluates each decision alternative in
terms of the best payoff that can occur. The strategy is best illustrated in
the payoff table repeated below.
Table 1.3.1
|
Decision Alternatives |
States
of Nature |
Maximum Payoff |
|
|
Low Demand, s1 |
High Demand, s2 |
||
|
Make Product, d1 |
($ 20,000) |
$ 90,000 |
$ 90,000 |
|
Buy Product, d2 |
$ 10, 000 |
$ 70,000 |
$ 70,000 |
|
Do Nothing, d3 |
$ 5,000 |
$ 5,000 |
$ 5,000 |
Note that an extra column is
added to record the maximum payoff for each decision alternative (maximum
payoff in each row of the table). The decision-maker employing the optimistic criterion
then selects the decision alternative associated with the maximum
of the maximum payoffs. Since $90,000 is the maximum of the
maximum payoffs, d1 is the selected decision. This strategy is
sometimes called the maximax strategy.
The "eternal optimist" would be one using this approach - it captures
the philosophy of decision-makers that accept risk of large losses to make
substantial gains.
Conservative Criterion
In this strategy, the decision-maker evaluates each decision alternative in
terms of the worst payoff that can occur. The payoff table is repeated here
with a new column to record the minimum payoffs for each decision alternative
(minimum payoff for each row in the table).
Table 1.3.2.
|
Decision Alternatives |
States
of Nature |
Minimum Payoff |
|
|
Low Demand, s1 |
High Demand, s2 |
||
|
Make Product, d1 |
($ 20,000) |
$ 90,000 |
($ 20,000) |
|
Buy Product, d2 |
$ 10, 000 |
$ 70,000 |
$ 10,000 |
|
Do Nothing, d3 |
$ 5,000 |
$ 5,000 |
$ 5,000 |
This strategy, which is sometimes
called the maximin strategy,
then selects that decision alternative associated with the maximum
of the minimum payoffs. In this situation, the decision-maker
would select d2, buy the product, since $10,000 is the maximum of
the minimum payoffs. Some believe this strategy is associated with
"eternal pessimists", but to be fair, it is actually a conservative
strategy used by decision-makers who seek to avoid large losses.
Compromise Minimax Regret Strategy
The third classic strategy for decision making under risk is called the minimax regret strategy, and is
neither purely optimistic nor conservative. This approach first starts by
converting the payoff table into a regret table. The regret table
looks at each state of nature, one at a time, and asks, "if I knew ahead
of time that state of nature s1 will occur, what would I do?"
The answer to maximize profit would be, "buy the product (d2)",
since that leads to the highest profit, $10,000. If the decision-maker selected
d2 and s1 occurred, there would be no regret. On
the other hand, if the decision-maker selected d3, there would be a
regret or opportunity loss of $5,000 ($10,000 that could have been gained minus
$5,000 that was gained). Similarly, there would be a regret of $30,000 if the
decision-maker selected d1 and state of nature s1
occurred ($10,000 that could have been gained minus the minus $20,000 loss).
The regret numbers for s2 are prepared in a similar fashion.
"If I knew ahead of time that state of nature s2 would occur,
what would I do?" The answer, again to maximize profit, is "make the
product (d1)," since that leads to the highest profit for s2,
$90,000. If the decision-maker selected d1 and s2
occurred, there would be no regret. On the other hand, if the decision-maker
selected d2, there would be an opportunity loss or regret of $20,000
($90,000 that could have been gained minus $70,000 that was gained). Likewise,
if the decision-maker selected d3 there would be a regret of $85,000
($90,000 minus $5,000). Table 1.3.3 illustrates the completed regret table.
Table 1.3.3.
|
Decision Alternative |
States
of Nature |
Maximum Regret |
|
|
Low Demand, s1 |
High Demand, s2 |
||
|
Make Product, d1 |
$ 30,000 |
$ 0 |
$ 30,000 |
|
Buy Product, d2 |
$ 0 |
$ 20,000 |
$ 20,000 |
|
Do Nothing, d3 |
$ 5,000 |
$ 85,000 |
$ 85,000 |
Next, I create a new column,
"Maximum Regret," to record the maximum regret value associated with
each decision strategy (the maximum regret in each row of the regret table).
This strategy, which is sometimes called the minimax
regret strategy, then selects that decision alternative associated with
the minimum of the maximum regrets. In this
situation, the decision-maker would select d2, buy the product,
since $20,000 is the minimum of the maximum regrets. Some believe this strategy
follows a "middle of the road" approach of minimizing losses.
Why don't you follow along with me while I illustrate the above strategies with
The Management Scientist software? First, I will click on the Start
button on the Windows Task Bar, then select Programs, then The
Management Scientist, then click on The Management Scientist icon,
select Continue, then click on Decision Analysis Module (Module Number
10), and we are ready to start a new problem.
Click on File, then New, then enter 3 decision
alternatives, 2 states of nature, click OK, and then enter the
numbers for the payoff table (omit the dollar signs and use a minus sign for
the negative $20,000). Next, select Solution, then Solve, keep
the default selection Maximize the Payoff, and then select Optimistic
Criterion to make your first run. You can then select to print this
solution, or better, save it to a file. I saved the solution to a
Management Scientist Out File. The Out files can be inserted into a Word document,
as I did below. In an open Word file, select Insert from the top tool
bar, then File, then search for your Management Scientist Out file (I
saved mine under The Management Scientist Folder so I "Looked In"
that folder, changed file type to "All Files" and opened the
appropriate out file to insert it below as Printout 1.3.1.
You may use this technique to e-mail computer output solutions to cases this
semester. You can open a Word document for your answer report, and insert the
Management Scientist Output file into the report following the above procedure.
Alternatively, you can write your answer narrative in an e-mail, then insert
the Management Scientist Out file into the e-mail, and forward to me. I can
easily open the Management Scientist Out file as a Word document and read your
output. If we ever experience e-mail problems, you can always print your
computer output files and fax them to me.
Now, back to the computer output, Printout 1.3.1, below.
Printout 1.3.1
DECISION ANALYSIS
*****************
YOU HAVE INPUT THE FOLLOWING PAYOFF TABLE:
******************************************
|
|
STATES OF NATURE |
|
|
DECISION |
1 |
2 |
|
1 |
- 20000 |
90000 |
|
2 |
10000 |
70000 |
|
3 |
5000 |
5000 |
DECISION RECOMMENDATION
***********************
USING THE OPTIMISTIC CRITERION
|
DECISION |
CRITERION |
RECOMMENDED |
|
1 |
90000 |
YES |
|
2 |
70000 |
|
|
3 |
5000 |
|
Note that the output
repeats your input, then provides the criterion column for making the decision,
as well as the recommended decision for the criterion selected. For practice,
go ahead and run "The Management Scientist" for the conservative and minimax regret criteria. Please note that the format of
your OUT file will be a little different than above as I had to insert tables
to conform to html format - you will not have to do that for a Word file.
This concludes the first approach to decision analysis: decision-making under
risk. One of the critiques of the approach is that it works with limited information
on the states of nature. Because of that, a second approach has been developed
to add information on the states of nature concerning their relative likelihood
of occurrence. That is our next section of material.
Module
1.4: Decision Making with Probabilities
In this approach, the
decision-maker has information concerning the relative likelihood of each of
the states of nature. It is sometimes called "decision making under
uncertainty." The criterion used in decision-making strategy with
probabilities is to select that decision so as to maximize the expected value
of the outcome. To illustrate the approach, let's refer again to the payoff
table for our make-buy example, this time adding a row for probabilities and a
column for the expected value of the decision alternatives.
Table 1.4.1
|
Decision Alternative |
States
of Nature |
Expected Value |
|
|
Low Demand, s1 |
High Demand, s2 |
||
|
Make Product, d1 |
($ 20,000) |
$ 90,000 |
$ 51,500 |
|
Buy Product, d2 |
$ 10,000 |
$ 70,000 |
$ 49,000 |
|
Do Nothing, d3 |
$ 5,000 |
$ 5,000 |
$ 5,000 |
|
Probabilities |
P (s1) = 0.35 |
P (s2) = 0.65 |
|
In decision analysis, it is
assumed that the probabilities are long-term relative frequencies. Since they are
often simply the subjective judgment of the decision- maker, the techniques is
subject to the criticism of this limitation. But this criticism can be levied
against any quantitative approach - the output is only as good as the input. To
counter the criticism, we will add a sensitivity analysis step after the
initial solution. For now, let's learn the expected value approach.
The expected value (EV) for a decision alternative is the sum of the
[probabilities of the states of nature times the payoffs]. For the "make
product" decision:
EV (d1) = [P (s1) * V11] + [P (s2) * V12]
= [0.35 * -20,000] + [0.65 * 90,000]
= $51,500
The
EV of $51,500 represents the long run outcome of repeated "make
product" experiments. That is, if we could theoretically conduct the
"make product" decision 100 times, 35 times we would lose $20,000,
and 65 times we would make $90,000. The weighted average of these outcomes is
$51,500. In reality, we do not conduct the experiment 100 times - we make the
decision once and we are either going to lose $20,000 or make $90,000. However,
and this is very important, we use the expected value approach to
assist us in making the decision.
I should add, at this point, that to abide by the laws of probability, each
probability must be a real number between 0 and 1, and the sum of the
probabilities for the states of nature must sum to one. For this to happen, the
states of nature must be mutually exclusive and exhaustive - that is, there
cannot also be a state of nature called, for example, medium demand. If there
was such a state of nature, it would have to be added to the payoff table and
accounted for with a third probability.
The expected values for the second and third decision alternatives are
calculated in a similar fashion. These are shown in Table 1.4.1. Following the
criterion of selecting that decision alternative which maximizes the expected
value of the outcome, we select decision alternative d1 as our
optimal or best strategy.
The expected value computations can be shown adjacent to the state of nature
nodes in the decision tree, as illustrated in Figure 1.4.1.
Figure 1.4.1
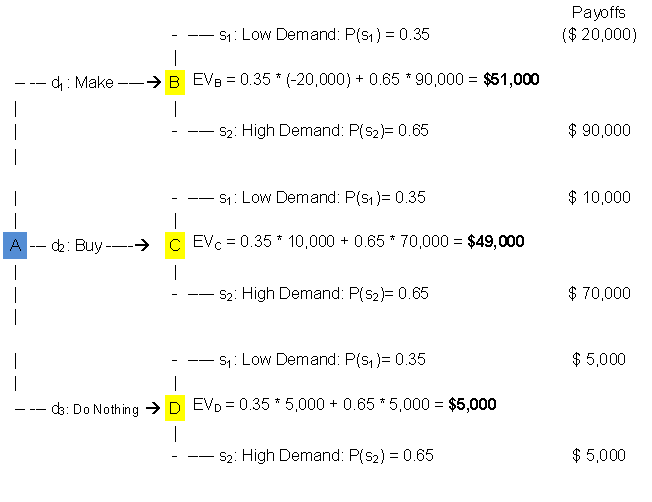
The
decision tree shows the expected value computations by each of the state of
nature nodes labeled B, C and D. Since the expected value for the
"make" decision" is the maximum, that decision branch is
selected as the optimum strategy. The "buy" and "do
nothing" branches are pruned, as indicated by the
crosshatched lines. The decision tree does not provide additional information,
it simply presents a picture of the decision strategy with probabilities.
Using The Management Scientist for Decision Making with Probabilities
Let's return to the software for a moment and rerun this example problem
using the expected value criterion for selecting a decision alternative.
After you open "The Management Scientist" program, click on File,
then New, then enter 3 decision alternatives, and 2 states
of nature just as before. This time, select State of
Printout 1.4.1
DECISION ANALYSIS
*****************
YOU HAVE INPUT THE FOLLOWING PAYOFF TABLE:
******************************************
|
|
STATES OF NATURE |
|
|
DECISION |
1 |
2 |
|
1 |
- 20000 |
90000 |
|
2 |
10000 |
70000 |
|
3 |
5000 |
5000 |
|
PROBABILITIES OF STATES |
0.35 |
0.65 |
DECISION RECOMMENDATION
***********************
USING THE EXPECTED VALUE CRITERION
|
DECISION |
CRITERION |
RECOMMENDED |
|
1 |
51,500.00 |
YES |
|
2 |
49,000.00 |
|
|
3 |
5000.00 |
|
EXPECTED VALUE OF PERFECT INFORMATION IS
10,500.00
The printout information
confirms the computations we made earlier in this section. For now, ignore the
Expected Value of Perfect Information shown at the bottom of the Decision
Recommendation. We will cover that in Section 1.5. Before that, we need to go
over a very important topic for any initial solution to any quantitative method
- sensitivity analysis.
Sensitivity Analysis
When you apply quantitative approaches to solve management problems it is
always a good idea to ask, "how sensitive is my solution to changes in
data input." This is especially true when the input consists of subjective
estimates. When the solution remains the optimal solution given large changes
in selected important inputs, there is a high level of confidence in the
solution. On the other hand, when the optimal solution strategy changes for
very small changes to the one or more inputs, the decision-maker should be
cautious before implementation. Perhaps some time should be spent in refining
the input.
Suppose the decision-maker examines the solution and realizes that the
"buy" decision lost out to the "make" decision by only
$2,500. Further suppose the decision-maker has little confidence in the payoff
for the "buy product" decision under the "high demand"
state of nature. The question is, "at what "buy product, high
demand" payoff would I be indifferent between the "make" and
"buy" decisions, given all other applicable data input items remain
the same?" To answer this question, we note that the point of indifference
occurs where the "make" and the "buy" EV's are equal.
Mathematically, this is expressed as the equation:
EVB = EVC
Now writing out the computational formulas for the EV's:
[P (s1) * V11] + [P (s2) * V12] = [P (s1) * V21] + [P (s2) * V22]
Now, substitute the data input values except for the unknown "buy product, high demand" payoff, V22:
[0.35 * -20,000] + [0.65 * 90,000] = [0.35 * 10,000] + [0.65 * V22]
Next, solve the equation for V22:
0.65 * V22 = 51,500 - [0.35 * 10,000]
V22 = 48,000 / 0.65
V22 = 73,846
So, if the decision-maker
erred by just 5.5% (estimates the "buy product, high demand" payoff
to be $70,000 when it is really $73,846), the decision-maker would have
selected the wrong strategy.
As a rule of thumb, if a decision strategy changes based on a five or less
percent change to an input, we say that the solution is very sensitive to
change and it might be wise to consider investing in more accurate data input
values.
Probabilities are sometimes also subjective estimates when there has been no
history or experience with a particular state of nature. By observation, we can
see that as long as P (s1) remains at or below 0.35 the
decision-maker will favor the optimal "make product" decision since a
low probability for s1 gives little relative weight to the $20,000
loss. But as P (s1) increases (resulting in a decrease for P (s2)),
the expected values approach a point of indifference or a break-even point. The
question is, at what P (s1) would the decision-maker be indifferent
between the "buy" and "make" decisions, all other data
input remaining the same?
Again, we begin by setting EVB equal to EVC to represent
break-even:
EVB = EVC
Next, we write out the computational formulas for the EV's:
[P (s1) * V11] + [P (s2) * V12] = [P (s1) * V21] + [P (s2) * V22]
Now, substitute the data input values except for the unknown state of nature probabilities:
[P (s1) * -20,000] + [P (s2) * 90,000] =
[P (s1) * 10,000] + [P (s2) * 70,000]
You may recall from an algebra class that we cannot solve one equation when there are two unknowns. However, recall that the sum of the probabilities of the states of nature must equal one. That is, with two states of nature:
P (s1) + P (s2) = 1
We can rewrite this as:
P (s2) = 1 - P (s1)
Then, we can substitute [1 - P (s1)] for each P (s2) in the break-even equation and continue solving for P (s1).
{P (s1) * -20,000} + {[1 - P (s1)] * 90,000} =
{P (s1) * 10,000} + {[1 - P (s1) * 70,000]}
Now simplify the equation:
- 20,000 P (s1) + 90,000 - 90,000 P (s1) =
10,000 P (s1) + 70,000 - 70,000 P (s1)
Finally, collect terms and solve for P (s1):
-110,000 P (s1) + 90,000 = - 60,000 P (s1) + 70,000
- 50,000 P (s1) = - 20,000
P (s1) = -20,000 / - 50,000 = 0.40
Conclusion: as long as P (s1)
stays less than or equal to 0.40, the "make" decision strategy will
remain the optimal strategy.
I was once involved in a decision analysis problem with a group of medical
doctors who owned their practice. The problem of interest was whether to pay of
a loan on a five-year schedule, or draw down cash and pay off the loan now. We
did a lot of sensitivity analysis on the probabilities attached to states of
nature representing the up or down swing of the economy in the next five years.
I know that working formula after formula on the white board in their office
would have been boring to the doctors. So instead, we used the computer
software package to simply give us results for all of the desired changes. The
point is, whether you use "brute force" by changing the input values
in the payoff and probability tables in the software package, or run a number
of break-even formulas, it is a good idea to always check how sensitive your
solution is to changes in the inputs.
What if you find out that your solution is sensitive to changes in the inputs.
In that case, it may be appropriate to obtain additional information concerning
your input numbers to make them more accurate or to increase your confidence in
their original value. However, while information has value, it is sometimes
expensive to obtain. Our last topic in decision analysis focuses on the value
of information.
I hope you are enjoying the first quantitative method of the course. This
technique has found countless applications in assisting managers make
decisions. I have personally helped companies use decision analysis in
equipment loan, construction, and enterprise resource planning situations. I
continue to believe that the formal steps in structuring the problem, which
forces the decision-maker to consider decision alternatives, states of nature, probabilities
and payoffs, is almost as valuable as coming up with the decision itself. As
well, every project I have worked on found considerable benefit from attention
to sensitivity analysis. Sorry for rambling - back to the subject.
1.5
The Value of Information
We made the point that
information has value, but it also costs money and time to obtain. So the
question becomes, how much would be willing to pay for additional information.
The upper limit is established by the first concept, the Value of Perfect
Information.
The Value of Perfect Information
Let's look at the payoff table once again.
Table 1.5.1
|
Decision Alternative |
States
of Nature |
Expected Value |
|
|
Low Demand, s1 |
High Demand, s2 |
||
|
Make Product, d1 |
($ 20,000) |
$ 90,000 |
$ 51,500 |
|
Buy Product, d2 |
$ 10,000 |
$ 70,000 |
$ 49,000 |
|
Do Nothing, d3 |
$ 5,000 |
$ 5,000 |
$ 5,000 |
|
Probabilities |
P (s1) = 0.35 |
P (s2) = 0.65 |
|
Suppose we knew ahead of the production
period which state of nature would occur - sort of like having a crystal ball. If we knew ahead of time that s1 would
occur, we would select d2 as our optimal strategy to maximize our
payoffs. If we knew ahead of time that s2 would occur, we would
select d1 to maximize our payoffs. Over time, the expected value
with this perfect information (abbreviated as EV w PI) would be:
EV w PI = [P (s1) * V21] + [P (s2) * V12]
= [ 0.35 * 10,000 ] + [ 0.65 * 90,000 ] = $62,000
Recall that without this perfect information, the expected value was $51,500 by going with d1. The difference between the expected value with perfect information and the expected value without perfect information is called the Expected Value of Perfect Information (EVPI):
EVPI = EV w PI - EV w/o PI = 62,000 - 51,500 = $10,500
EVPI places an upper bound on how much we
should be willing to pay someone to get additional information on the future
states of nature in order to improve our decision making strategy.
For example, we might be willing to pay a consultant for a market research
study to help us learn more about the demand states of nature. We don't expect
the research study to result in perfect information, but we hope it will
represent a good proportion of the $10,500. We also know that we do not want to
pay more than $10,500 for the new information.
New information about the states of nature takes the form of revisions to the
probability estimates in decision analysis. This information may be obtained
through market research studies, product testing or some other sampling
process. In decision analysis, this topic is called the Expected Value of
Sample Information.
The Expected Value of Sample Information (EVSI)
Recall that we have probabilities on the states of nature, P (s1)
and P (s2). These are more technically called prior probabilities.
If we plan to obtain sample information, the results will be expressed as
revisions to these prior probabilities.
Suppose a market research consultant offers to conduct a demand analysis that
will result in two indicators. I1 will be the
indicator used to represent a prediction of low demand in the
next production period. I1 then corresponds to the state of nature
we labeled s1, the difference is that one is a prediction and one is
an actual occurrence. I2 will be the indicator used to represent a
prediction of high demand in the next production period. This indicator
corresponds to our state of nature s2.
This indicator information will be used to calculate conditional probabilities.
P (s1 given I1) will be the probability that s1
will occur given or conditioned on the consultant's I1 prediction. P
(s1 given I1) is generally written as P (s1 |
I1). Since there are two states of nature and two indicators, we
will need three additional conditional probabilities, P (s1 | I2),
P (s2 | I1) and P (s2 | I2).
In order to compute these conditional probabilities and then EVSI, we need to
know the consultant's track record. That is, how has the consultant done in
prior market demand studies? In terms of decision analysis, we want to know the
accuracy of indicator predictions given what state of nature actually occurred.
Suppose the following information is available from the consultant.
Table 1.5.2.
|
State of |
Market
Research |
|
|
Predict Low Demand, I1 |
Predict High Demand, I2 |
|
|
Low Demand, s1 |
P ( I1 | s1 )
= 0.90 |
P ( I2 | s1 )
= 0.10 |
|
High Demand, s2 |
P ( I1 | s2 )
= 0.20 |
P ( I 2 | s2 )
= 0.80 |
We are almost there, but note that these conditional probabilities are the reverse
of what we need. To get from P (I1 | sj)
to P (sj | I1), we need to set
up a table and do some calculations. Same for Indicator 2. Let's do I1
first.
Table 1.5.3.
|
States of sj |
Prior
Probabilities, |
Consultants Track |
Joint
Probabilities, |
Conditional
Probabilities, |
|
s1 |
P (s1) =
0.35 |
P (I1|s1)
= 0.90 |
0.35*0.90 = 0.315 |
P( s1| I1)=.315 /
0.445 =0 .708 |
|
s2 |
P (s2) =
0.65 |
P (I1|s2)
= 0.20 |
0.65*0.20 = 0.13 |
P( s2| I1 )
=0.13/0.445 = 0.292 |
|
|
|
|
P(I1)=.315
+ .13 =0.445 |
Note: 0.708 + 0.292
= 1.00 |
The first three columns in Table
1.5.3 are from input information. The joint probabilities column is computed by
multiplying the prior probabilities times the consultant track record
probabilities in each row. The conditional probabilities in the last column are
computed by dividing the joint probabilities by P(I1).
Note how consultant research information can change the estimates on the probabilities.
Now the probability of low demand becomes 0.71 given that the consultant
predicts low demand, and taking into account the consultant's track record.
This revision reflects prior accuracy for the low demand case. Note that the
probability of high demand, s2 goes from 0.65 to 0.29 given that the
consultant predicts that demand will be low.
I believe the above steps illustrate the power of the complete decision
analysis technique. The steps illustrate how information has value to justify
its expense. Now, we do similar calculations for Indicator two in Table 1.5.4.
Table 1.5.4.
|
States of sj |
Prior
Probabilities, |
Consultants Track |
Joint
Probabilities, |
Conditional
Probabilities, |
|
s1 |
P (s1) =
0.35 |
P (I2|s1)
= 0.10 |
0.35*0.10 = 0.035 |
P( s1| I2)=.035 /
0.555 = 0 .063 |
|
s2 |
P (s2) =
0.65 |
P (I2|s2)
= 0.80 |
0.65*0.80 = 0.52 |
P( s2| I2 )=0.52 /
0.555 = 0.937 |
|
|
|
|
P(I2)=.035
+ .52 =0.555 |
Note: 0.063 + 0.937
= 1.00 |
Although we will use the
computer to produce the above conditional probabilities as well as the
following results, it is instructive to picture the decision problem
incorporating the sample information. This is done in the decision trees in
Figure 1.5.1, 1.5.2 and 1.5.3.
Figure 1.5.1

Figure
1.5.1 shows a new decision to our problem: the decision of whether or not to
engage the services of the market research consultant. If the manufacturer does
not engage the services, the expected value has already been determined to be
$51,500 by selecting d1, "make " the product. Note that I
have added the expected value that would be obtained should the decision maker
engage the services of the marketing consultant, $58,400. The first event after
engaging the services of the consultant is the consultant's predictions.
The consultant's predictions are then followed by the manufacturer's decisions
to "make,", "buy," or "do nothing;" which are
then followed by the actual states of nature, low and high demand. Figure 1.5.2
illustrates the decision tree leading from the node labeled C in Figure 1.5.1,
the consultant's prediction of low demand.
Figure 1.5.2.

This
part of the decision tree provides back-up for the calculation of the $27,500 expected
value for node 3. That value represents the highest expected value and is
associated with the "buy" decision. Thus, if the consultant is hired
to conduct the market research, and predicts low demand, the best decision is
to "buy" the product. When working out decision trees by hand, we
always start at the right of the tree, move left, pruning branches coming from
decision nodes as we go. You should observe that every state of nature node
gets an expected value computation, the sum of the products of probabilities
times payoffs. Every decision node simply gets the highest expected value from
its branches.
Next we examine the computations for the node labeled D in Figure 1.5.1., the
event that occurs if we engage the consultant and the consultant's prediction
is high demand. This is shown in Figure 1.5.3.
Figure 1.5.3.
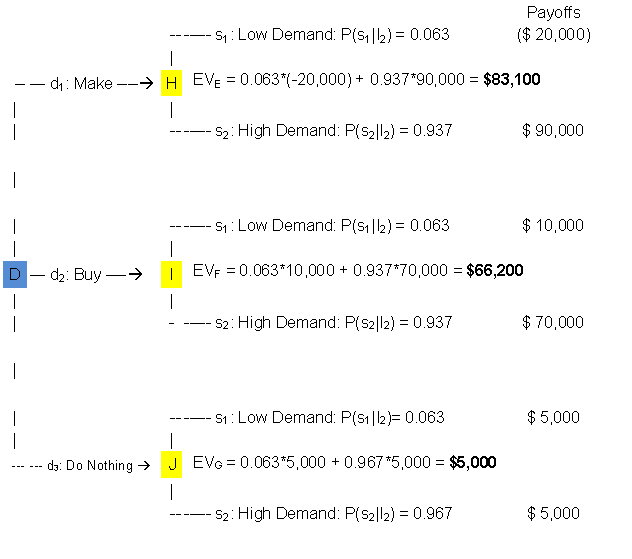
This part of the decision
tree provides back-up for the calculation of the $83,100 expected value for
node D. That value represents the highest expected value and is associated with
the "make" decision. Thus, if the consultant is hired to conduct the
market research, and predicts high demand, the best decision is to
"make" the product.
Looking back at Figure 1.5.1, we see that the expected value with the market
research consultant report, named the expected value with sample
information (EV w SI), is $58,400. The expected value without the
sample information (EV w/o SI) (same as the expected
value without perfect information) is $51,500.
To get the expected value of sample information, we just make the
subtraction:
EVSI = EV w SI - EV w/o SI = 58,400 - 51,500 = $6,900
Like EVPI, this is a powerful
piece of information. We now know how much we would be willing to spend to
obtain market research from the consultant - that is a great bargaining chip to
have at negotiation time!
Efficiency of the Sample Information
Pause and Reflect
Recall that the expected value of perfect information was $10,500 - that placed a theoretical upper bound on how much we would be willing to spend for perfect information. But forecasts and consultants are not perfect. If we can get the "track record" of a forecaster consultant, we can then determine how they stack up to the theoretical EVPI.
To compute the efficiency of the sample information, we simply divide the EVSI by EVPI and convert the decimal to a percent:
Efficiency = EVSI / EVPI = 6,900 / 10,500 = .657 = 65.7 %
The closer this number is to
100%, the better.
I am not suggesting that every decision analysis exercise includes this last
procedure of computing EVSI and its efficiency. Often the track record of the
sample information producer may not be available. But when it is (and it should
ALWAYS be available if you do the market research "in-house", this is
a powerful tool to put some limits on how much you would want to spend to
acquire more information.
I appreciate that the computation of EVSI is tedious - it has taken me hours to
produce the decision trees in power point, convert them to html images and
insert them into to these pages (I am not complaining - I always wanted to
learn how to convert power point slides to html text images and now I know!).
Fortunately, "The Management Scientist" does all of this work for us.
We will close this first module with a demonstration of the computer output for
EVPI and EVSI.
Using "The Management Scientist" for Computing EVPI and EVSI
Open up the software program as before. This time, when you select the
Decision Analysis Module, then file, and enter a new problem,
click State of
When you select solve, the following file can either be printed or saved
to a Management Scientist Out file.
Printout 1.5.1
DECISION ANALYSIS
*****************
YOU HAVE INPUT THE FOLLOWING PAYOFF TABLE:
******************************************
|
|
STATES OF NATURE |
|
|
DECISION |
1 |
2 |
|
1 |
- 20000 |
90000 |
|
2 |
10000 |
70000 |
|
3 |
5000 |
5000 |
|
PROBABILITIES OF STATES |
0.35 |
0.65 |
DECISION RECOMMENDATION
***********************
USING THE EXPECTED VALUE CRITERION
|
DECISION |
CRITERION |
RECOMMENDED |
|
1 |
51,500.00 |
YES |
|
2 |
49,000.00 |
|
|
3 |
5000.00 |
|
EXPECTED VALUE OF PERFECT INFORMATION IS 10,500.00
DEVELOPING A DECISION STRATEGY BASED ON SAMPLE INFORMATION
**********************************************************
YOU HAVE INPUT THE FOLLOWING PROBABILITIES FOR INDICATOR OUTCOMES:
******************************************************************
|
GIVEN |
INDICATOR |
INDICATOR |
|
1 |
0.90 |
0.10 |
|
2 |
0.20 |
0.80 |
OPTIMAL DECISION STRATEGY
*************************
|
IF |
BEST |
EXPECTED |
INDICATOR |
|
1 |
2 |
27,528.09 |
0.445 |
|
2 |
1 |
83,063.06 |
0.555 |
EXPECTED VALUE OF THE ABOVE STRATEGY 58,350.00
EXPECTED VALUE OF THE SAMPLE INFORMATION 6,850.00
EFFICIENCY OF THE SAMPLE INFORMATION 65.2%
You should be able to pick out
all of the terms and their values in the computer output from our discussion.
Please note that I rounded my expected value computations to the nearest 100 so
that my numbers will not be as accurate as the computer output. I should also
note that there are special decision analysis software packages, even one
created by Microsoft. The special packages have the same capabilities as our
text package, plus many more features. For example, the special packages will
"draw" the decision tree, allow multiple branching such as state of
nature branches followed by more state of nature branches, and handle much
larger problems than 10 decision nodes. The special packages also cost in the
$100's and only do decision analysis. Our package may have limitations but it
includes 11 other modules!
Well, that's it! You should now be ready to work the first case assignment.
Please e-mail any questions that you may have.
That finishes our first quantitative method. I believe decision analysis is a
good place to start since it illustrates the five-step decision-making process
in a picture called the decision tree. The tree shows the decision alternatives
to the problem, the factors that effect the
alternatives (states of nature and their probabilities), the outcomes of
decision alternatives (payoffs) and the criterion for selection (maximize
expected value). Please note that our illustration involved maximize expected
value - if you were working a minimize problem (such as select alternatives so
as to minimize costs) you would simply indicate that criterion at the
appropriate input screen.
| Return to Module Overview | Return to top of page |